ARM带来四款新的移动GPUIP:一律全新架构
除了面向64位移动计算的 Cortex-X2 、 Cortex-A710、Cortex-A510三款全新CPUIP,ARM今天还带来了多达四款新的移动GPUIP,同样启用新的命名规则,分别是Mali-G710、Mali-G610、Mali-G510、Mali-G310。
G710、G510、G310分别定位旗舰、主流、入门级市场,依次取代现有的G78、G57、G310。
G610其实和G710是一回事儿,只是核心数较少时单独使用的名字。
这是ARM Valhall GPU架构的第三代产品,也是第一次完整覆盖高中低端各个领域。
搭配同时发布的Cortex-X2/A710/A510 CPU、CoreLink CI-700一致性互连技术、CoreLink NI-700芯片网络一起,它们可以构成完整、强大的SoC解决方案。
虽然架构变化不大,只是继续优化提升,但是这一代Mali GPU的性能进步还是很可观的:
G710号称综合性能提升20%、机器学习性能提升35%、纹理性能提升50%、能效提升20%。
G510综合性能提升100%、机器学习性能提升100%、能效提升22%。
G310虽然定位最低但变化最大,号称纹理性能提升多达6倍、Vulkan性能提升4.5倍、安卓UI内容性能提升2倍。
G710的执行引擎设计和G77、G78十分相似,变化更多是一些细节。
wavefront/warp大小从8翻番到了16,而且每个执行引擎有两个数据路径,最终形成每个核心32个FMA。
ISA指令集也有了不小的改进,可以更好地满足Vulkan等现代GPU的需求,但暂无细节。
G710还新增了一个执行引擎,每个着色器核心的计算性能因此翻番,同时每核心每时钟周期的不同吞吐量也有4倍、8倍的增加。
纹理单元也是全新的,每时钟周期可以处理最多80亿纹理,再加上面积优化,单位密度纹理性能提升了50%。
16宽度执行单元单实例变成了4宽度四实例,整体吞吐量不变,但是资源分配更合理,效率更高。
新的执行引擎每核心每时钟周期FMA翻了一番,同时功耗也优化降低了20%。
另外,传统的工作管理器(Job Manager)变成了新的“指令流前端”(Command Stream Frontend),负责调度和处理draw-call,还第一次带来了固件层,与硬件紧密配合处理主机需求。
G710可以配置8-16个不同核心数,G610则是最多6个核心,另外二级缓存可以配置2个或4个区块,每个区块256KB或者512KB, 也就是整体最小512KB,最多2MB。
G510支持2-6个核心配置,每核心每执行单元的配置也可以定制,纹理单元也大大加强。
执行引擎还是2个,但也可以配置为只用1个,每时钟周期64 FMA会因此减少到48 FMA。
ARM列举了G510 10种可能的不同规格配置,计算能力、填充率各有不同,适合不同应用需求。
G310虽然定位最低,但这次升级力度最大,终于抛弃了古老的Bifrost架构。
它因此有了新的执行引擎设计,支持灵活的规模配置,每核心可以有16、32、48、64 FMA,纹理单元最低则是每时钟周期2个。
不过,G310仅支持单核心设计。
相关推荐
-
 macOS 换用 ARM 来势汹汹!Win10 ARM 到底失败在哪里
macOS 换用 ARM 来势汹汹!Win10 ARM 到底失败在哪里
-
ARM创始人表示:如果被英伟达收购 将是一场灾难
-
英国干预英伟达收购ARM花旗银行:最新报告指出收购
-
Pycharm激活码无限用 两种主要的激活方式分享
-
ARM新品发布会定了:全新一代X2/A79超大核来了,你
-
NVIDIA将逐步停产RTX 20系列GPU芯片
-
NV要发新一代核弹GPU?短时间内RTX 3090 Ti可能就
-
英伟达表示:第一季度,挖矿专用CMP GPU带来了1.55
-
 揭秘开普勒GK110架构 七彩虹GTX780s参考价4399元
揭秘开普勒GK110架构 七彩虹GTX780s参考价4399元
-
 联信科技携手漱玉平民大药房,提供更贴心的智能健康
联信科技携手漱玉平民大药房,提供更贴心的智能健康
-
 金士顿京东618开门红 限时五折抽大奖
金士顿京东618开门红 限时五折抽大奖
-
 易来(Yeelight)携手联信科技,为全球客服中心再添
易来(Yeelight)携手联信科技,为全球客服中心再添
-
 游戏仓库 金士顿NV1 M.2 NVMe固态硬盘装机体验
游戏仓库 金士顿NV1 M.2 NVMe固态硬盘装机体验
-
 一加618玩狠的,一加9系列购机至高优惠500元
一加618玩狠的,一加9系列购机至高优惠500元
-
 聚焦“神经末梢”布建,亚略特场景化AI助推小区安防
聚焦“神经末梢”布建,亚略特场景化AI助推小区安防
-
 陈洁kiki敦煌直播首秀,揭秘这场最火城市直播
陈洁kiki敦煌直播首秀,揭秘这场最火城市直播
-
 让小区装上“超级大脑的神经末梢”,亚略特场景化AI
让小区装上“超级大脑的神经末梢”,亚略特场景化AI
-
 一加 9R 青宇配色开启预售,8GB+256GB惊喜到手价2999元
一加 9R 青宇配色开启预售,8GB+256GB惊喜到手价2999元
-
 OnePlus Watch 赛博朋克 2077 限定版开启预售,售价1299元
OnePlus Watch 赛博朋克 2077 限定版开启预售,售价1299元
-
 场景化AI向后厨不规范行为说不 智慧阳光厨房已成为
场景化AI向后厨不规范行为说不 智慧阳光厨房已成为
-
 直播买货周年开启新征程,坚持创新助力数字化转型
直播买货周年开启新征程,坚持创新助力数字化转型
-
 EPSON × 腾讯极光联名投影测评:影院级沉浸体验
EPSON × 腾讯极光联名投影测评:影院级沉浸体验
-
 电子烟行业新锐黑马,COEE可逸势不可挡
电子烟行业新锐黑马,COEE可逸势不可挡
-
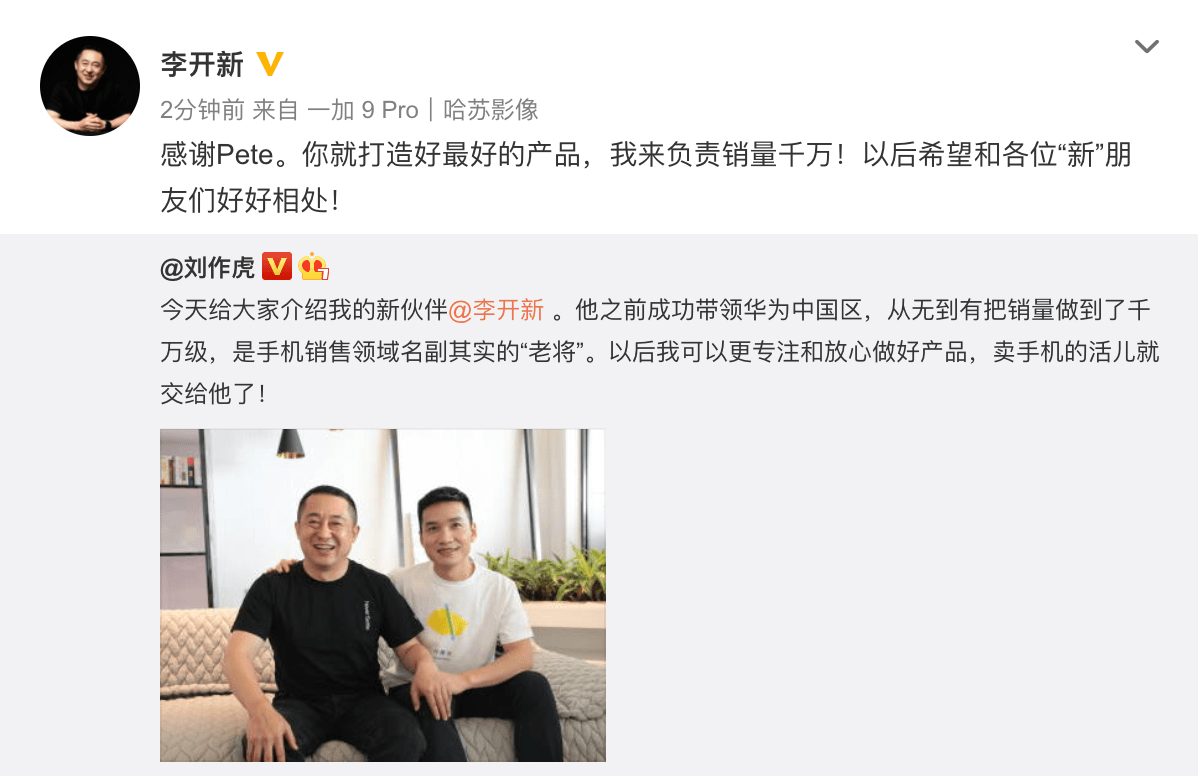 前华为中国区副总裁李开新入职一加手机 销量目标剑
前华为中国区副总裁李开新入职一加手机 销量目标剑
-
 玩转欧蓝德露营之旅,探秘热河谷体验生活新乐趣
玩转欧蓝德露营之旅,探秘热河谷体验生活新乐趣
-
 刘润、卫哲领衔 托比网联合创业酵母推出《创变:数
刘润、卫哲领衔 托比网联合创业酵母推出《创变:数
-
 BOE(京东方)重磅亮相国际显示周 五大创新领域展
BOE(京东方)重磅亮相国际显示周 五大创新领域展
-
 HyperX与红牛电竞车队展开全新合作
HyperX与红牛电竞车队展开全新合作
-
 HyperX携手非营利组织RAD开展心理健康公益活动
HyperX携手非营利组织RAD开展心理健康公益活动